Multimedia Signal Processing
Image Processing
Thorsten Thormählen
June 23, 2023
Part 6, Chapter 1
Thorsten Thormählen
June 23, 2023
Part 6, Chapter 1
This is the print version of the slides.
Advance slides with the → key or
by clicking on the right border of the slide
Slides can also be advanced by clicking on the left or right border of the slide.
| Type | Font | Examples |
|---|---|---|
| Variables (scalars) | italics | $a, b, x, y$ |
| Functions | upright | $\mathrm{f}, \mathrm{g}(x), \mathrm{max}(x)$ |
| Vectors | bold, elements row-wise | $\mathbf{a}, \mathbf{b}= \begin{pmatrix}x\\y\end{pmatrix} = (x, y)^\top,$ $\mathbf{B}=(x, y, z)^\top$ |
| Matrices | Typewriter | $\mathtt{A}, \mathtt{B}= \begin{bmatrix}a & b\\c & d\end{bmatrix}$ |
| Sets | calligraphic | $\mathcal{A}, B=\{a, b\}, b \in \mathcal{B}$ |
| Number systems, Coordinate spaces | double-struck | $\mathbb{N}, \mathbb{Z}, \mathbb{R}^2, \mathbb{R}^3$ |

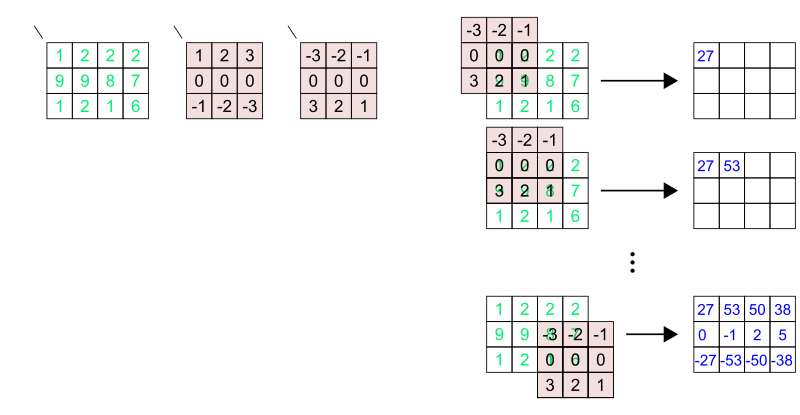
 Original |
 3 x 3 |
 5 x 5 |
 7 x 7 |
 21 x 21 |
|
Original |
 3 x 1 |
 5 x 1 |
 7 x 1 |
 21 x 1 |
|
Original |
 1 x 3 |
 1 x 5 |
 1 x 7 |
 1 x 21 |
|
Original |
 3 x 3 |
 5 x 5 |
 7 x 7 |
 21 x 21 |
 Original |
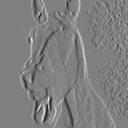 x-direction
$\frac{1}{8}\begin{bmatrix}1 & 0 & -1\\
2 & 0 & -2\\
1 & 0& -1 \end{bmatrix}$
|
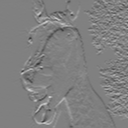 y-direction
$\frac{1}{8}\begin{bmatrix}1 & 2 & 1\\
0 & 0 & 0\\
-1 & -2& -1 \end{bmatrix}$
|

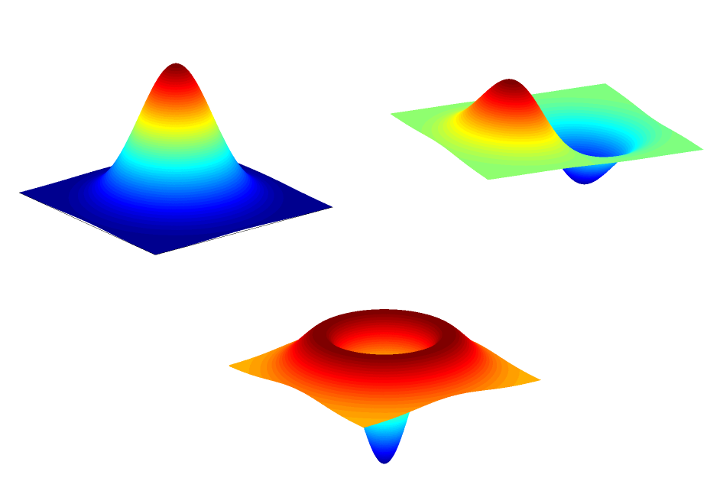
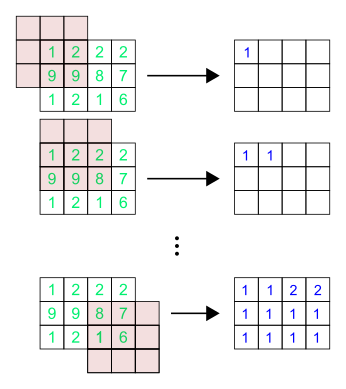

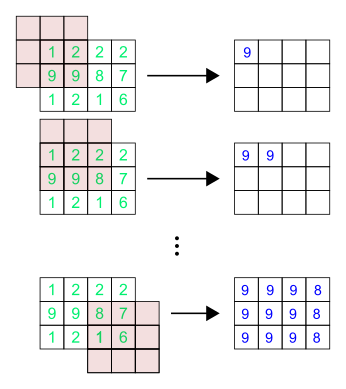



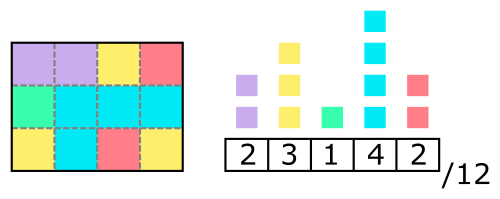




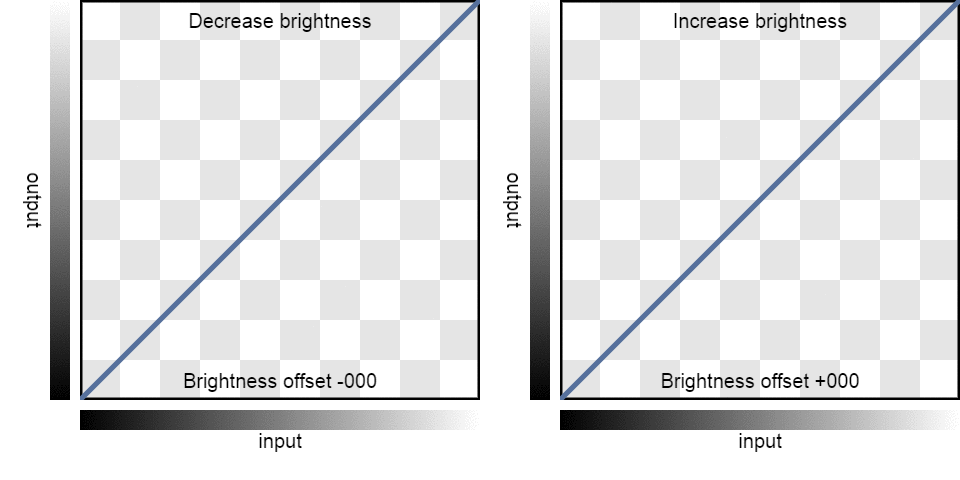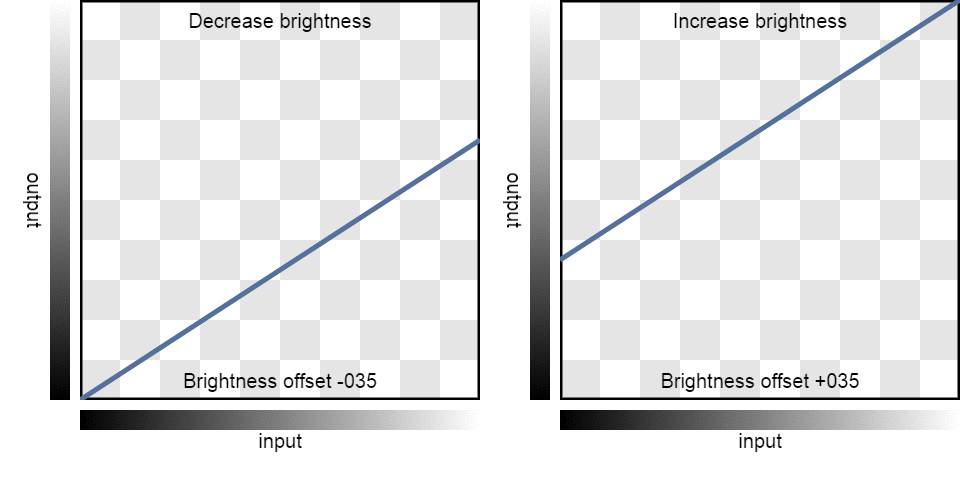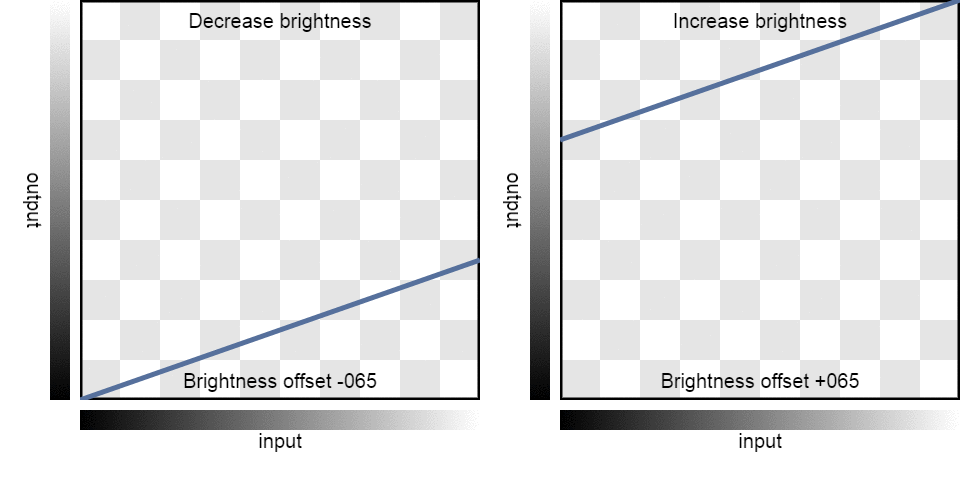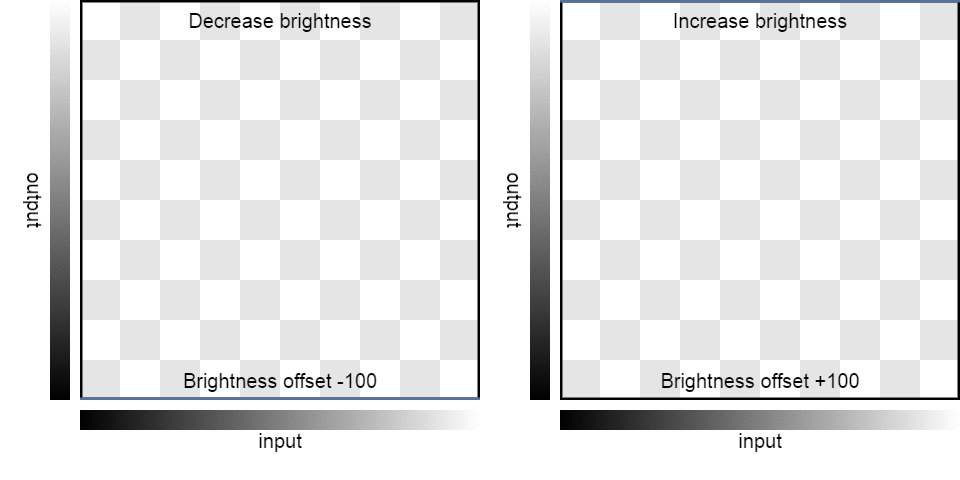
| Brightness: | -100 | -75 | -50 | -25 | 0 | 25 | 50 | 75 | 100 |
| Result: |  |
 |
 |
 |
 |
 |
 |
 |
 |
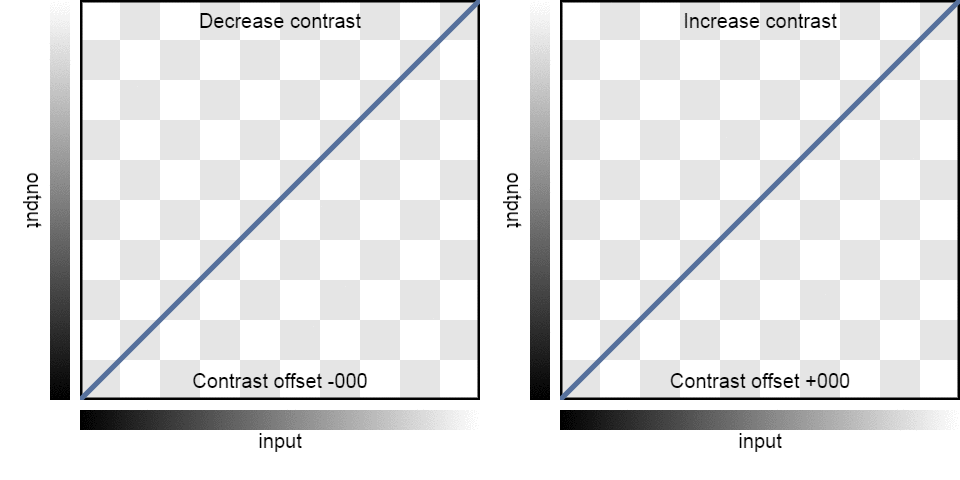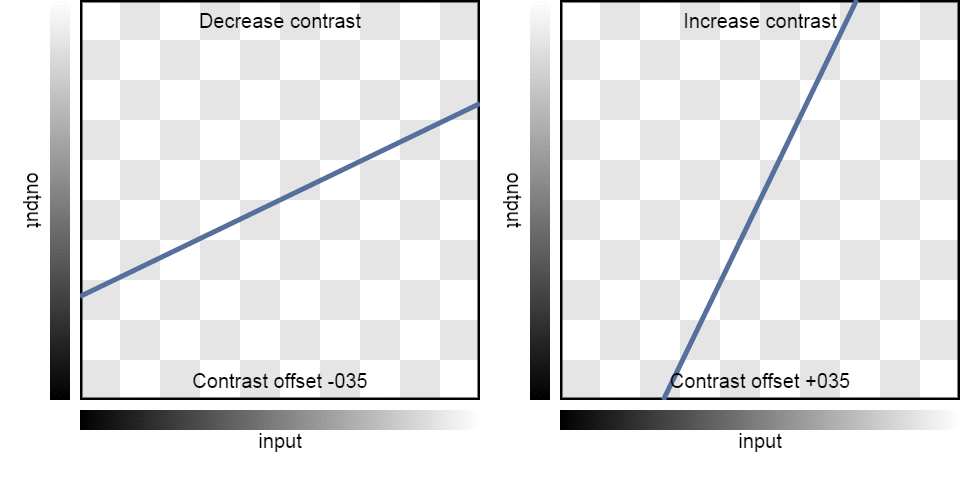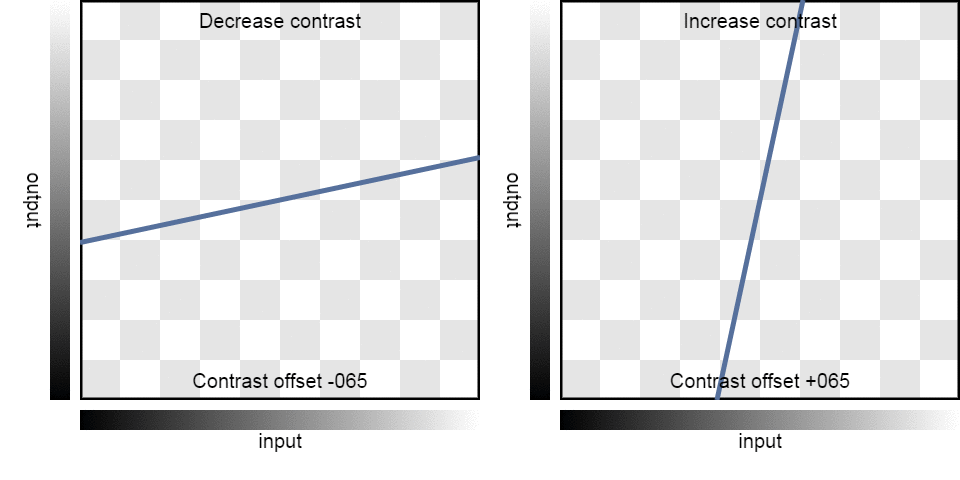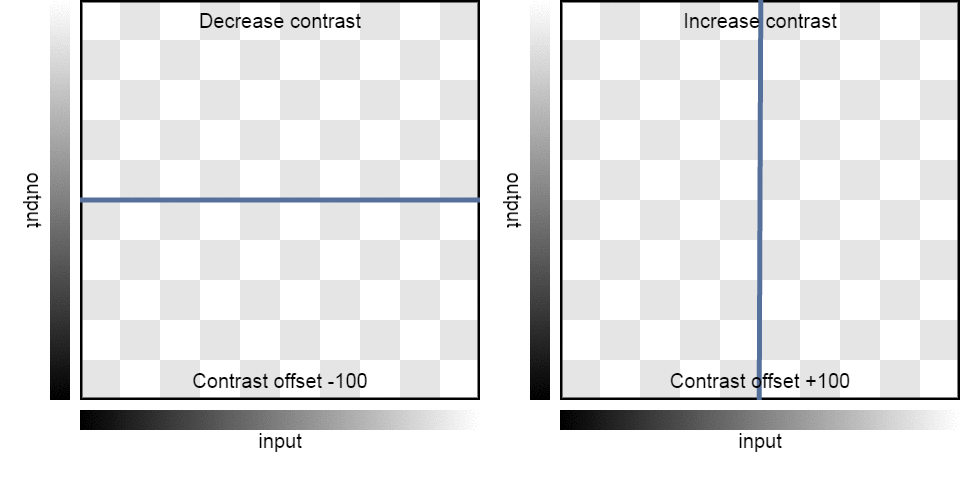
| Contrast: | -100 | -75 | -50 | -25 | 0 | 25 | 50 | 75 | 100 |
| Result: |  |
 |
 |
 |
 |
 |
 |
 |
 |

Please notify me by e-mail if you have questions, suggestions for improvement, or found typos: Contact