Technische Informatik I
FPU, MMX, SSE, x86-64
Thorsten Thormählen
30. Januar 2018
Teil 10, Kapitel 3
Thorsten Thormählen
30. Januar 2018
Teil 10, Kapitel 3
Dies ist die Druck-Ansicht.
Weiterschalten der Folien durch die → Taste oder
durch das Klicken auf den rechten Folienrand.
Das Weiterschalten der Folien kann ebenfalls durch das Klicken auf den rechten bzw. linken Folienrand erfolgen.
| Typ | Schriftart | Beispiele |
|---|---|---|
| Variablen (Skalare) | kursiv | $a, b, x, y$ |
| Funktionen | aufrecht | $\mathrm{f}, \mathrm{g}(x), \mathrm{max}(x)$ |
| Vektoren | fett, Elemente zeilenweise | $\mathbf{a}, \mathbf{b}= \begin{pmatrix}x\\y\end{pmatrix} = (x, y)^\top,$ $\mathbf{B}=(x, y, z)^\top$ |
| Matrizen | Schreibmaschine | $\mathtt{A}, \mathtt{B}= \begin{bmatrix}a & b\\c & d\end{bmatrix}$ |
| Mengen | kalligrafisch | $\mathcal{A}, B=\{a, b\}, b \in \mathcal{B}$ |
| Zahlenbereiche, Koordinatenräume | doppelt gestrichen | $\mathbb{N}, \mathbb{Z}, \mathbb{R}^2, \mathbb{R}^3$ |

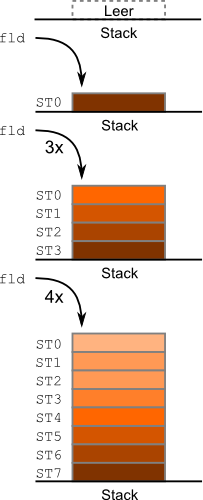
ST0, ST1, ..., ST6, ST7fld zum Laden eines Registers bezieht sich immer auf ST0
ST0 immer das oberste Element des Stapelspeichersfld geladen (d.h. auf den Stapel gelegt) werden die Daten an das nächste Register weitergereicht:ST7=ST6, ST6=ST5, ..., ST1=ST0, ST0=neuer Wert
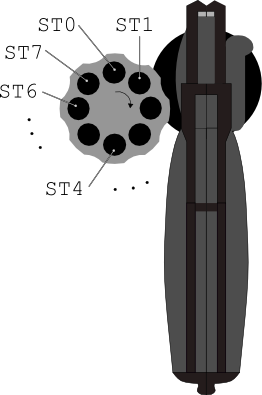
ST0 kann immer an der "12 Uhr" Position abgelesen werden, von ST1 bei "1:30 Uhr", von ST2 bei "3 Uhr", usw.fld kann nur über die oberste Kammer an der "12 Uhr" Position (also über ST0) erfolgenST0 geschrieben ST0 Wert wird ungültig. Beispiel (Quelldatei: main.cpp):
int main() {
float a = 1.1f;
float b = 0.3f;
double c = 0.6f;
__asm {
fld a;// ST0=1.1
fld b;// ST1=1.1, ST0=0.3
fld c;// ST2= 1.1, ST1=0.3, ST0=0.6
fld a;// ST3= 1.1, ST2=0.3, ST1=0.6, ST1=0.1
fld b;// ST4= 1.1, ST3=0.3, ST2=0.6, ST1=0.1, ST0=0.1
fld c;// ST5= 1.1, ST4=0.3, ST3=0.6, ST2=0.1, ST1=0.1, ST0=0.6
fld a;// ST6= 1.1, ST5=0.3, ST4=0.6, ST3=0.1, ST2=0.1, ST1=0.6, ST0=1.1
fld b;// ST7= 1.1, ST6=0.3, ST5=0.6, ST4=0.1, ST3=0.1, ST2=0.6, ST1=1.1, ST0=0.3
fld c;// the stack (revolver cylinder) is full
fld a;// values are still shifted but overwritten ones are invalid
}
}
ST0 Registers mit einer Gleitkommazahl kann der Befehl fld verwendet werden
fld quelle
quelle eine Speicheradresse sein, an der die Gleitkommazahl im RAM abgelegt ist, oder
ein anderes FPU-Register: ST1, ..., ST7
int main() {
float a = 1.1f;
float b = 0.3f;
double c = 0.6f;
__asm {
fld a ;// ST0=1.1
fld b ;// ST1=1.1, ST0=0.3
fld c ;// ST2= 1.1, ST1=0.3, ST0=0.6
fld st(0) ;// ST3= 1.1, ST2=0.3, ST1=0.6, ST0=0.6
fld st ;// ST4= 1.1, ST3=0.3, ST2=0.6, ST1=0.6, ST0=0.6
fld st(3) ;// ST5= 1.1, ST4=0.3, ST3=0.6, ST2=0.6, ST1=0.6, ST0=0.3
}
return 0;
}
ST0 Register als Gleitkommazahl können die Befehle fst und fstp verwendet werden
fst ziel fstp ziel
ziel eine Speicheradresse sein oder
ein anderes FPU-Register: ST1, ..., ST7
fst nur speichert, entfernt fstp das oberste Element vom Stack (engl. "store pop"). fstp: Die Kugel wird an ST0 entnommen und an ziel abgelegt
und dann die Trommel gegen den Urzeigersinn gedreht
int main() {
float a = 1.1f;
float b = 0.3f;
double c = 0.6f;
__asm {
fld a ;// ST0=1.1
fld b ;// ST1=1.1, ST0=0.3
fst c ;// c=0.3
fst st(2) ;// ST2=0.3, ST1=1.1, ST0=0.3
fstp st(3) ;// ST2=0.3, ST1=0.3, ST0=1.1
}
return 0;
} Quelldatei: main.cpp
| Befehl | Beschreibung |
|---|---|
fild | Laden einer vorzeichenbehafteten ganzen Zahl |
fist | Speichern einer vorzeichenbehafteten ganzen Zahl |
fistp | Speichern und herausschieben ("pop") einer vorzeichenbehafteten ganzen Zahl |
int main() {
int a = 10;
int b = 20;
__asm {
fild a ;// ST0=10
fild b ;// ST1=10, ST0=20
fistp b ;// b=20;
fistp b ;// b=10;
}
return 0;
}| Befehl | Beschreibung |
|---|---|
fadd ziel, quelle | Addiert ziel und quelle. Wenn kein Ziel angegeben, gilt ziel=ST0 |
faddp ziel, quelle | Wie fadd, anschließend herausschieben ("pop") von ST0 |
fsub ziel, quelle | Subtrahiert ziel und quelle. Wenn kein Ziel, gilt ziel=ST0 |
fsubp ziel, quelle | Wie fsub, anschließend herausschieben ("pop") von ST0 |
fdiv ziel, quelle | Dividiert ziel und quelle. Wenn kein Ziel, gilt ziel=ST0 |
fdivp ziel, quelle | Wie fdiv, anschließend herausschieben ("pop") von ST0 |
fmul ziel, quelle | Multipliziert ziel und quelle. Wenn kein Ziel, gilt ziel=ST0 |
fmulp ziel, quelle | Wie fmul, anschließend herausschieben ("pop") von ST0 |
fabs | Berechnet den Betrag von ST0 |
fchs | Ändert das Vorzeichen von ST0 |
fyl2x | Berechnet ST1 = ST1 $\cdot \log_2($ST0$)$, und "pop" von ST0 |
fsqrt | Berechnet die Quadratwurzel von ST0 |
| Befehl | Beschreibung |
|---|---|
fld1 | Laden von 1.0 |
fldl2e | Laden von $\log_2 e$ |
fldl2t | Laden von $\log_2 10$ |
fldlg2 | Laden von $\log 2$ $(= \log_{10} 2)$ |
fldln2 | Laden von $\ln 2$ $(= \log_{e} 2)$ |
fldpi | Laden von $\pi = 3.141592...$ |
#include <stdio.h>
#include <math.h>
float myLog(float x) {
float result;
__asm {
fldln2 ;// load log_e(2) in ST0
fld x ;// load ST0=x; ST1=log_e(2)
fyl2x ;// ST1 = log_e(2)*log_2(x) = log_e(x); pop;
fstp result; // store ST0 in result; pop;
}
return result;
}
int main() {
float x = 25.0;
float result = myLog(x);
printf("ln(%f) = %f \n", x, result); // output result of myLog
printf("ln(%f) = %f \n", x, log(x)); // check result with C log function
return 0;
} Quelldatei: main.cppST0 Register zurückgegeben#include <stdio.h>
#include <math.h>
float myLog(float x) {
__asm {
fldln2 ;// load log_e(2) in ST0
fld x ;// load ST0=x; ST1=log_e(2)
fyl2x ;// ST1 = log_e(2)*log_2(x) = log_e(x); pop;
}
}
int main() {
float x = 25.0;
printf("ln(%f) = %f \n", x, myLog(x)); // output result of myLog
printf("ln(%f) = %f \n", x, log(x)); // check result with C log function
return 0;
} Quelldatei: main.cppMM0, MM1, ..., MM7 angesprochenpadd, psub, pmul, pxor, pand, por, usw.
s (= "signed") vorzeichenbehaftete Operanden oderus (= "unsigned") vorzeichenlose Operanden handelt| Suffix | Größe der Operanden |
|---|---|
b | Byte (1 Byte) |
w | Word (2 Bytes) |
d | Double Word (4 Bytes) |
q | Quad Word (8 Bytes) |
paddusw steht für welche Operation?paddusw mm0, mm1addiert vier vorzeichenlose 16-Bit Zahlen

#include <stdio.h>
int main() {
char text[] = "go fast!";
char subMe[] = { 32, 32, 0, 32, 32, 32, 32, 0 };
printf("%s \n", text);
__asm {
movq mm0, text ;//move 64 bits into mm0 register
psubsb mm0, subMe ;//substract content of "text" and "subMe" in parallel
movq text, mm0
emms ;// emms = Empty MMX Technology State (reactivate FPU registers)
}
printf("%s \n", text);
return 0;
}
Quelldatei: main.cppXMM0, XMM1, ..., XMM7ps ("Packed Single-precision"), z.B.
addps, subps, mulps, divps usw.,
können vier 32-Bit-Gleitkommazahlen gleichzeitig von einem Befehl verarbeitet werdenpd ("Packed Double-precision"),
können zwei 64-Bit-Gleitkommazahlen gleichzeitig von einem Befehl verarbeitet werdenss ("Scalar Single-precision") und
sd ("Scalar Double-precision"). Bei Befehlen mit diesen Suffixen ist der
eine Operand ein Skalar und kein Vektormov-Befehlen kennzeichnet ein weiteres Suffix, ob die Speicheradresse,
an der die Werte gelesen bzw. geschrieben werden sollen, auf ein Vielfaches von 16 Byte fällt:
movaps ("move aligned")
verwendet werdenmovups ("move unaligned") #include <stdio.h>
int main() {
float a[] = { 1.0f, 2.0f, 3.0f, 4.0f };
float b[] = { 1.1f, 2.2f, 3.3f, 4.4f };
float s = 2.0f;
for (int i = 0; i < 4; i++) printf("a[%d] = %f\n", i, a[i]);
__asm {
movups xmm1, a ;//load 4 floats = 128 bit
movups xmm2, b ;//load 4 floats = 128 bit
addps xmm1, xmm2 ;//add all 4 floats in parallel
addss xmm1, s ;//add scalar s to 1st float, 2nd - 4th float remain unchanged
movups a, xmm1 ;//store into a
}
for (int i = 0; i < 4; i++) printf("a[%d] = %f\n", i, a[i]);
return 0;
} Quelldatei: main.cppR gekennzeichnetRAX, RBX, ... RSP zur Verfügung.
Die niederwertigen Teile davon können mit den älteren Bezeichnungen EAX, AX, AH, AL, etc. angesprochen werden R8, .. , R15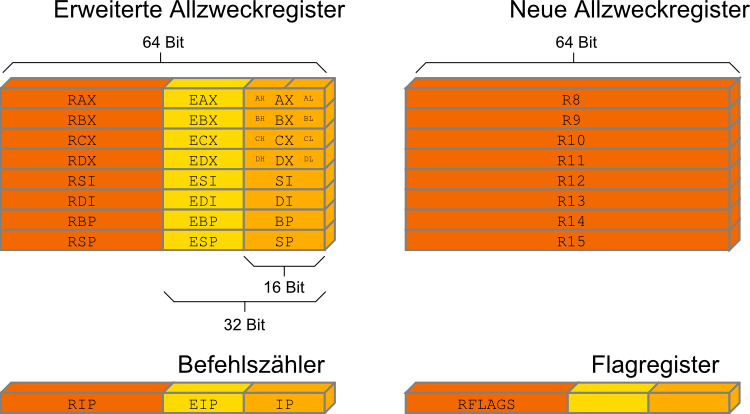

Anregungen oder Verbesserungsvorschläge können auch gerne per E-mail an mich gesendet werden: Kontakt